
Data Modelling
Data modelling is the process of organizing and structuring data to make it easier to analyze and use for decision-making. It defines how data is stored, accessed, and inter-connected. It creates a visual sketch that represents the relationships between datasets which can then be used for analysis. Data modelling ensures that data is accurate, consistent, and optimized for business needs.
Data modelling is an important concept because it helps to organize raw data into logical structures like tables and relationships, making it easier to manage and analyze. It reduces redundancy, improves data consistency, and supports faster querying. It is also scalable as data grows and evolves, enabling better decision-making with clean, well-structured data.
How to design an effective Data Model
Designing an efficient data model requires an understanding of the data and their relationships. A well-designed data model minimizes errors and ensures scalability.
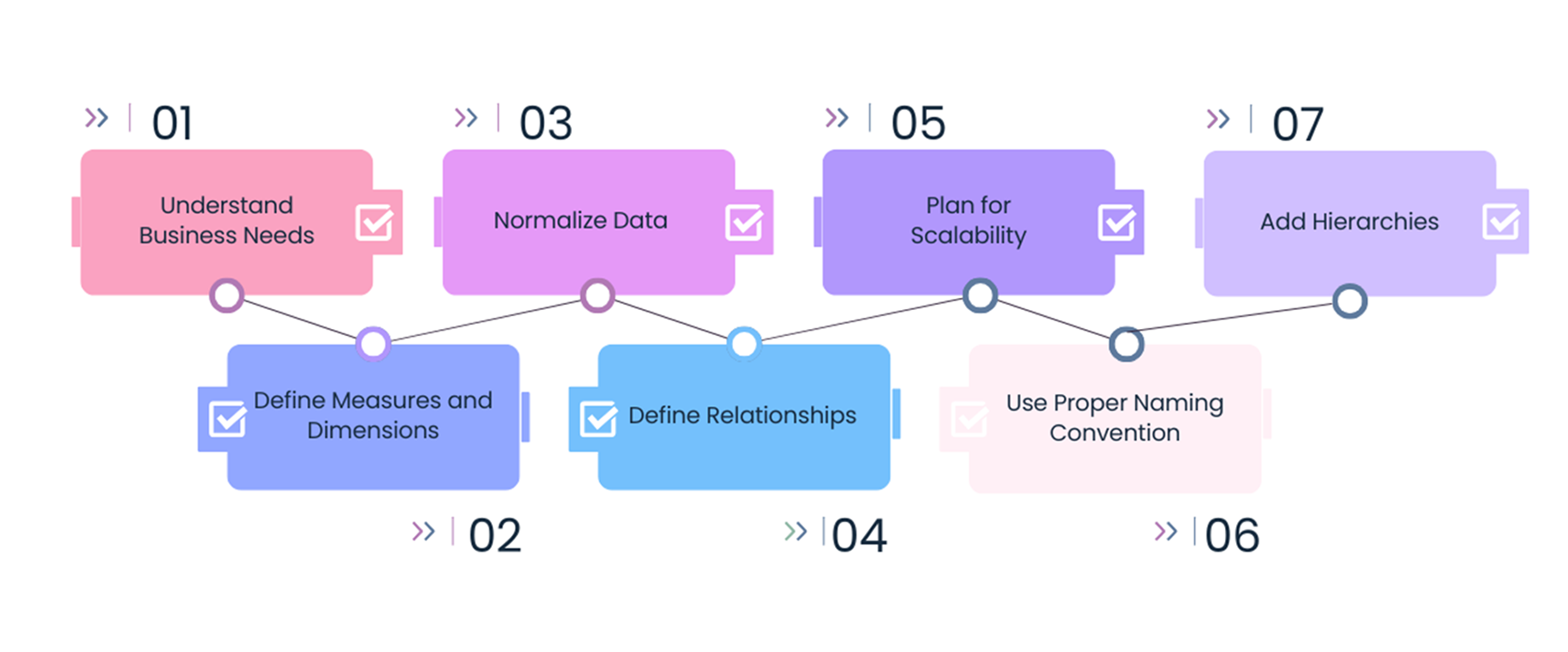
Steps to build an effective data model:
- Understand Business Needs: Talk to stakeholders to learn what data they need and how they plan to use it. Identify key questions the model should answer, like tracking sales or understanding customer behavior.
- Define Measures and Dimensions: Define measures (e.g., Total Sales) and dimensions (e.g., Product Category) to make the data more useful for reports and visualizations.
- Normalize Data: Break large tables into smaller ones to reduce duplication and keep data consistent. Each table should have a clear purpose and store data in its simplest form.
- Define Relationships: Determine how the entities connect. For example, a customer can place many orders, and an order can include multiple products. Use primary and foreign keys to link tables and define relationships like one-to-one, one-to-many, or many-to-many.
- Plan for Scalability: Design the model to handle more data as the business grows. Add indexes to columns frequently used in queries to speed up performance.
- Use Proper Naming Convention: Name tables and columns in a way that is easy to understand. Avoid abbreviations or confusing technical terms so everyone can work with the data easily.
- Add Hierarchies: Include hierarchies like Year → Quarter → Month for better analysis.
Components of Data Modelling
-
Fact Tables: These tables store quantitative data or metrics, such as sales, revenue, or profit. They are the core of data analysis and are linked to dimension tables.
-
Dimension Tables: These tables store descriptive data that provides context for fact tables. They allow users to filter, group, or analyze data from different perspectives.
-
Relationships: Relationships link fact tables and dimension tables using key columns. This enables querying data efficiently by joining relevant tables.
-
Hierarchies: A hierarchy organizes data into levels, such as year → quarter → month, for data logical relationships between levels of data.
Types of Data Models
Data models come in three types: conceptual, logical, and physical.
- Conceptual data model focuses on the entities involved and their relationships without going into technical details.
- Logical model defines the detailed structure of data in a system and explains how different data elements relate to each other. it builds on the high-level ideas from the conceptual model by adding specific attributes, relationships, and rules. this model serves as a base for creating the physical model, which is implemented in a database.
- Physical model implements the structure in a database with specific tables, columns, and keys.
The relationships, established using primary and foreign keys, form the foundation of data models like star and snowflake schemas.
How to define a relationship between datasets
In the earlier sections, we have learnt about Fact and Dimension tables and how they fit into a Star schema. Let us look at these tables in the Star schema and understand how they are interconnected in a data model.
The key column is a unique identifier that creates logical connections between tables.
- Primary Key: Uniquely identifies records in a table, such as a LoanID in the Loan Fact table in the above section.
- Foreign Key: References the primary key in another table to link related records.
Common relationship types include
One-to-Many: One-to-many relationships, the most common type, connect a single record in one table to multiple records in another, enabling structured data analysis. For instance, each Branch (Branch ID) manages multiple loans (Loan ID), but each loan belongs to only one branch.
Many-to-one: Multiple records in one table map is linked back to a single record in another table. For example, multiple loans (Loan ID) are tied to the same Product (Product ID), such as Home Loan.
Many-to-many: Many-to-many relationships require a junction table to link multiple records from one table to multiple records in another. Customers (Customer ID) can have multiple loans (Loan ID), and each loan has a status (Status ID) like Approved, Pending, or Rejected. The Status ID simplifies tracking of loan statuses for each customer across multiple loans.
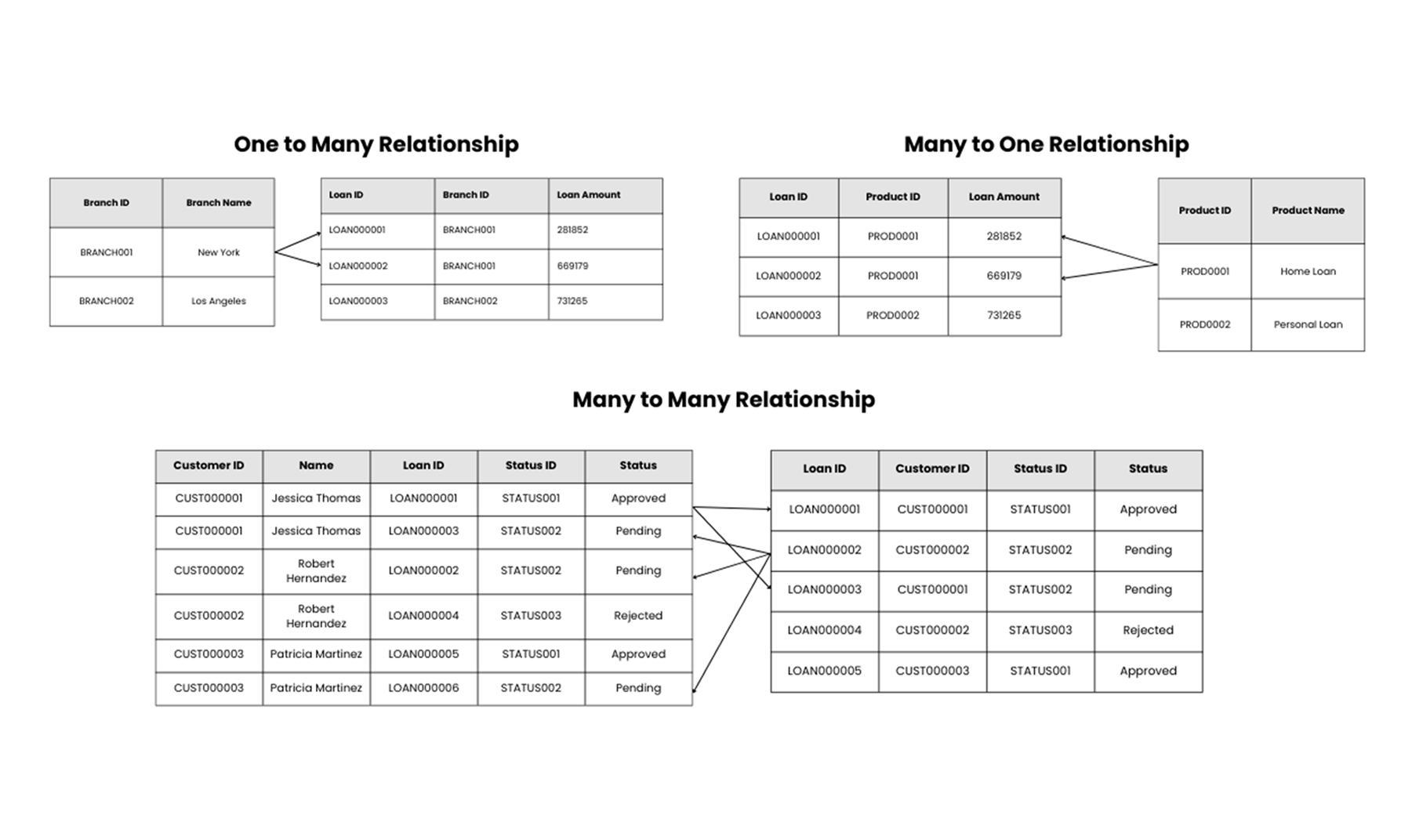
These relationships form the foundation of star schemas, where a central fact table links to multiple dimensions. They organize data models, ensure accuracy, and enable efficient queries, making them crucial for effective data management.
After understanding the fundamentals of data modelling, including the relationships between fact and dimension tables and their role in structuring data, it is time to apply these concepts practically. Infoveave provides a platform to create efficient and scalable data models. The next section explores how to use Infoveave to define measures, configure dimensions, and establish relationships between tables, to create a star schema.